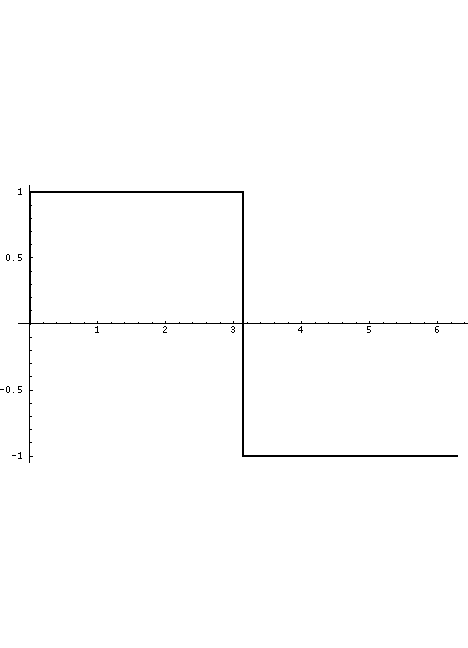
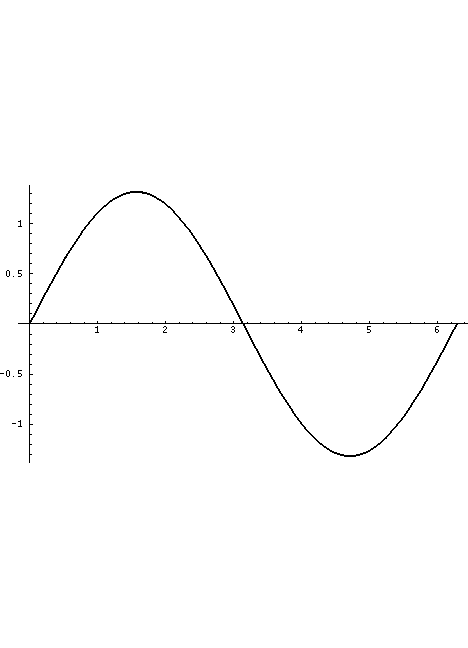
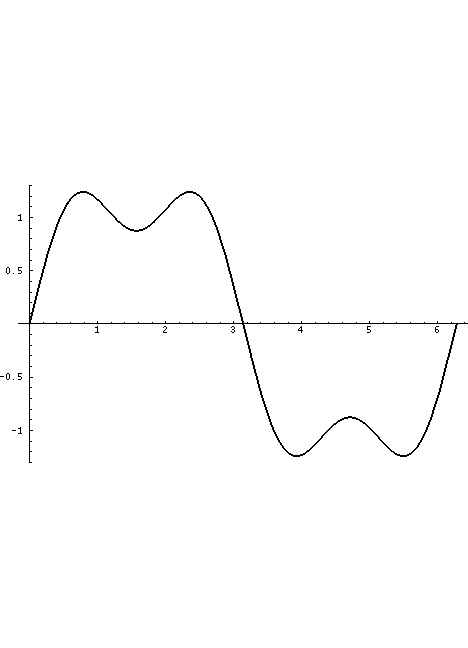
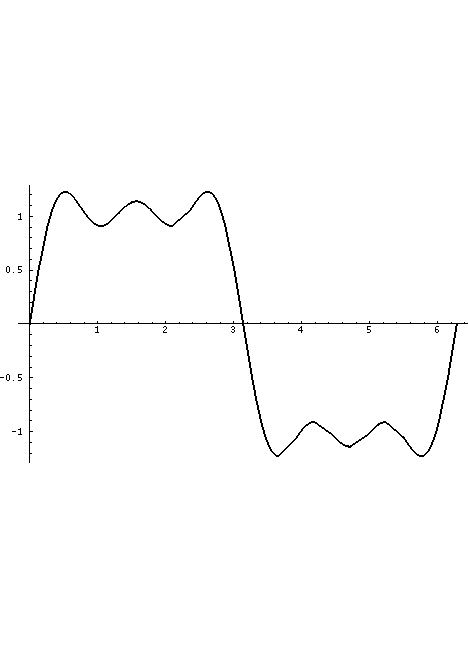
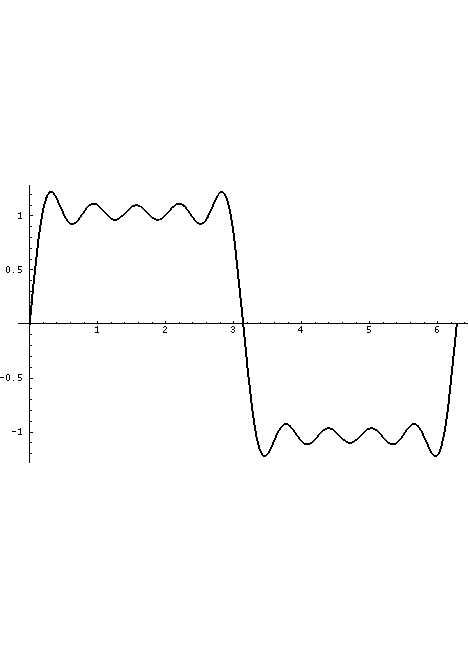
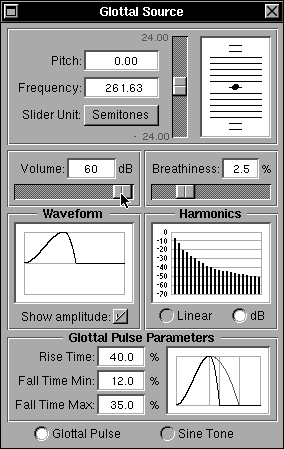
The volume flow through the glottis is roughly a triangular wave with a single discontinuity at closure which generally produces all harmonics of the fundamental glottal rate, falling off at roughly 12dB per octave with increasing harmonic frequency (remember, the dB scale is power-based with zero being an arbitrary reference power). This is what is displayed in the Waveform sub-panel.
Glottal Pulse Parameters
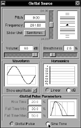
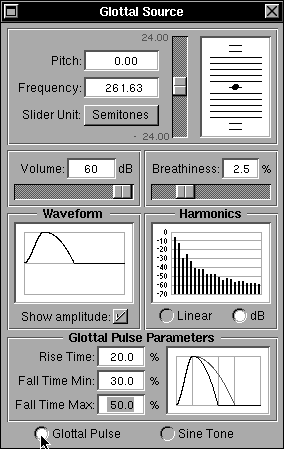
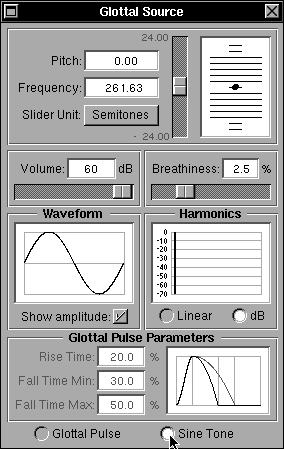
Fig 16a: Adjusting the rise and fall times for the glottal pulse
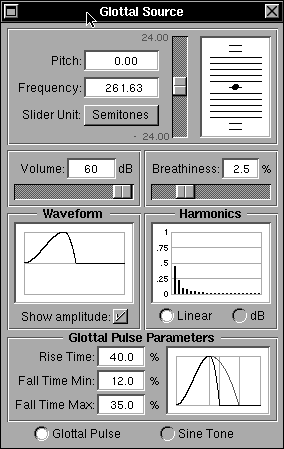
Fig 16b: Substituting sine wave excitation for the glottal pulse
The question of which artificial glottal pulse shape gives the most natural sounding voice has been a subject of research for decades. Our choice was the “Rosenburg B” waveform that is almost identical in shape to “Rosenberg C” as seen in the “Waveform” sub-panel. As an aid to visualisation, the Rosenberg C waveform comprises of a raised half sine wave joined smoothly to a quarter sine wave at twice the amplitude. The “Rosenberg B” is made of polynomial functions and, as noted, is almost indistinguishable. Both provide a smooth onset with a sharp termination (a single discontinuity in both first and second order derivatives) and the “B” version was experimentally judged by listeners to produce the most natural voice quality when substituted for the original glottal pulse in speech recomposed from a decomposition of natural speech (Rosenberg 1971) and has a slightly sharper offset so a little more high frequency content than the “C” version (which was a close second). A total of six artificial glottal pulse shapes were tested. A second experiment looked at the rise and fall times of the “C” waveform. The defaults chosen for Synthesizer are in the rise/fall region judged most natural in that experiment. The broader topic is usefully discussed in Witten (1982 pp 95-101) in connection with the excitation of resonance synthesisers which excite formant filters rather than a tube analogue. The fact remains that natural glottal excitation sounds better than even the best artificial glottal excitation, and also carries some speaker identification information.
Ideally, given enough knowledge and computational power, a proper aerodynamic model of the vibrating vocal folds would be used to excite the TRM. We would expect this to improve the naturalness of the voice quality significantly. Vocal fold/glottis modelling is a very active area of research. There is to be a conference on the topic in Marseille, France in August 2004 (Int Conf on Voice Physiology and Biomechanics August 18-20). Google on “vocal fold modeling” to gain access to a wide variety of research.
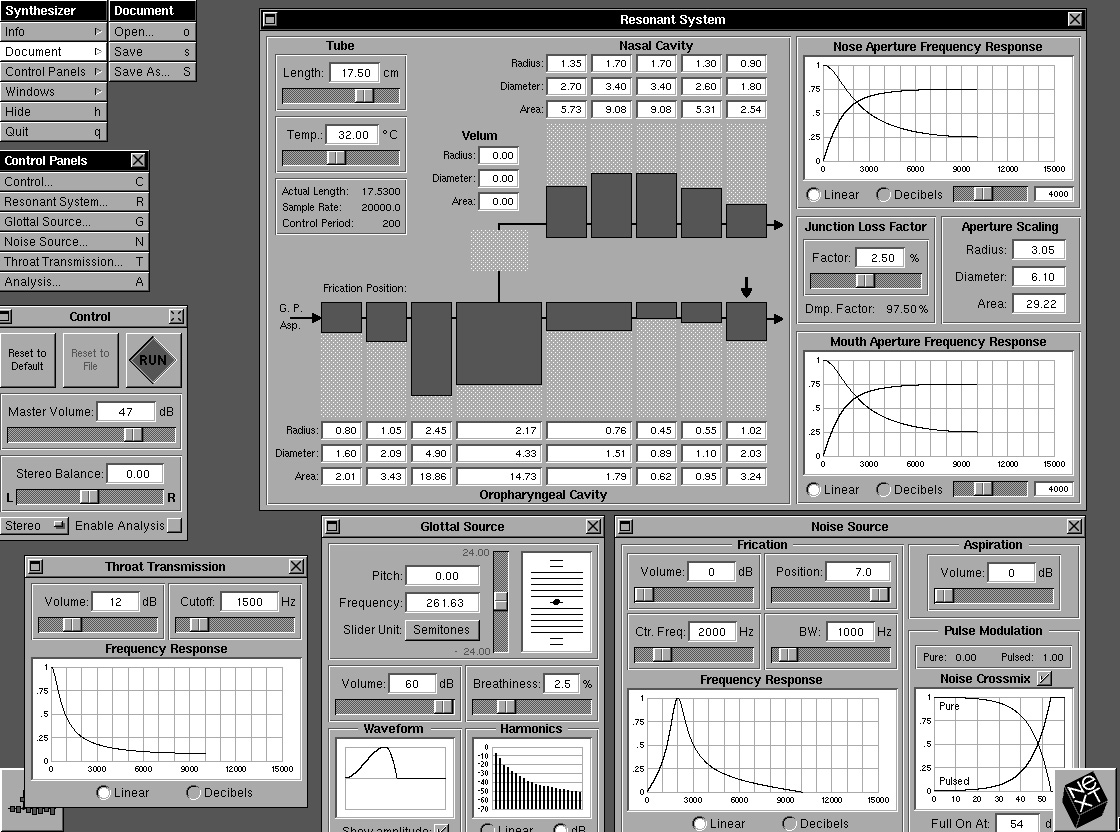
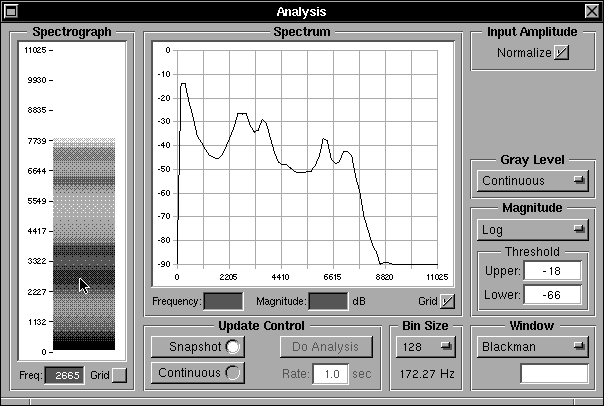
The parameters of the glottal pulse -- the rise and fall times -- can be varied as a percentage of the total glottal period using fields within the Glottal Pulse Parameters sub-panel at the bottom. The maximum duration of the fall time can also be set -- a value that is used during the wavetable calculations of the amplitude-varying glottal pulse -- effectively extending the fall period as the amplitude decreases, but limited by the maximum fall time set. The range for all three time parameters is limited from 5% to 50% of the total period. The parameters also control a nominal pulse shape display to the right of the same sub-panel with a greyed portion for the maximum. Figure 16a shows a situation in which the parameters have been changed from their default values.

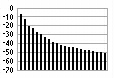
Fig 16c: Waveform and harmonics display
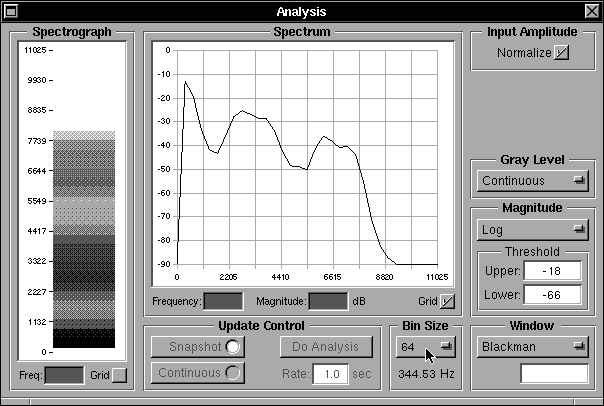
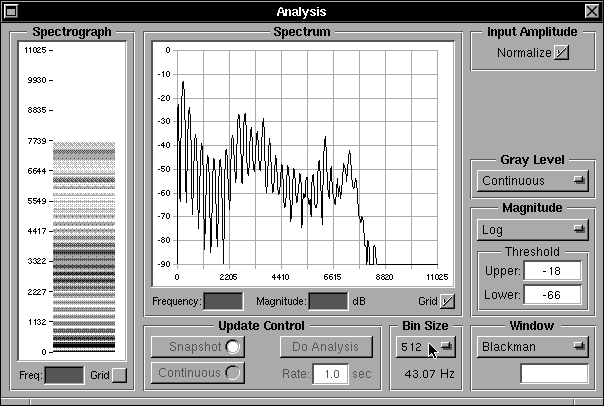
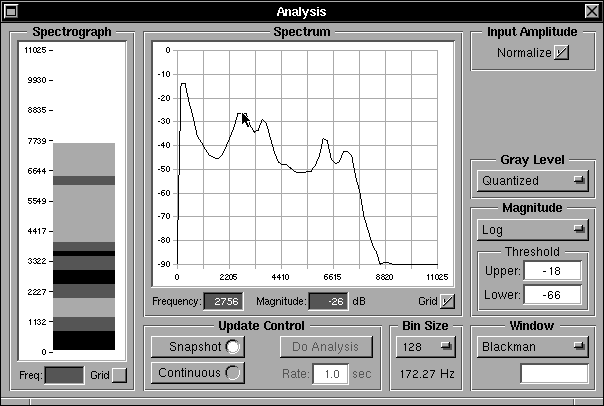
Immediately above the Glottal Parameters sub-panel lie the Waveform and Harmonics sub-panels which show the glottal pulse shape and the corresponding harmonic spectrum respectively. These respond to the glottal pulse parameter settings. If the radio buttons at the bottom of the main panel below the Glottal Pulse Parameters sub-panel are set to “Sine Tone” instead of “Glottal Pulse” the Waveform display changes to show a full cycle sine wave and the Harmonics display shows a single harmonic corresponding to the sine wave as shown in Figure 16b. The sine wave input can be used for test purposes, sweeping a single frequency through a range to examine the tube response to a pure tone. The Harmonics display can be swtiched from a dB display relative to the maximum harmonic to a linear display, using the radio buttons below the harmonics display, as shown in figure 16c.
Provided the “Show amplitude” check box just below the Waveform display is checked, the changes in shape and variation in fall time can be seen by changing the "Rise Time", "Fall Time Min." and "Fall Time Max." settings and varying the “Volume” control just above the Waveform display. The “Volume” control changes the amplitude of the pulse. The change in duration of the fall as the amplitude changes can be seen more easily by not checking the box, because then the displayed amplitude does not change according to the actual pulse amplitude.
Adjusting the pitch value

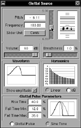
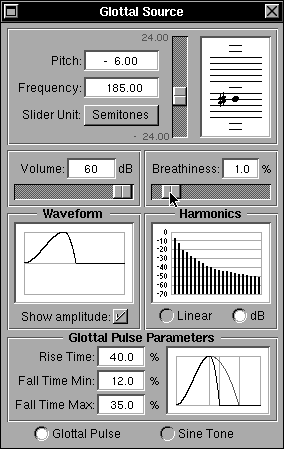
Fig 17a: Adjusting the pitch value: semintones
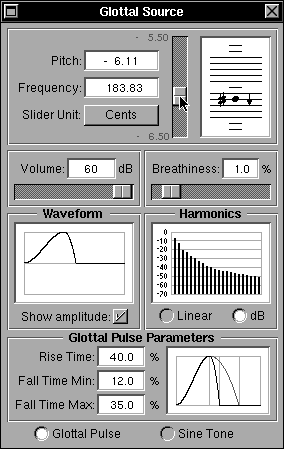
Fig 17b: Adjusting the pitch value: Cents
The frequency of the glottal pulse, or sine wave, is set at the top of the main panel using several controls plus a display of the musical note equivalent of the pitch. “Pitch” shows the TRM parameter value directly which nominally varies between +24 and -24, although this range does get slightly extended when necessary. “Frequency” shows the physical frequency corresponding to the pitch. Both fields may be entered directly, or the slider may be used to vary the pitch.Figure 17a shows a pitch adjustment away from the default value based on semitone adjustment
The “Slider Unit” pull-down allows “Semintones” or “Cents” to be selected as the units of change. The Cent is a logarithmic interpolation within a semi-tone and provides 100 logarithmic steps. Thus there are 1200 cents per octave since an octave is 12 semitones. If Cents are selected, then, as the pitch value is changed, the range of movement is restricted to one semi-tone and an up arrow or down arrow appears beside the musical note display according to whether the current setting is somewhat above or somewhat below the musical note displayed. Figure 17b shows the resulting change in the displays. The musical scale is calibrated to A = 440 Hz so that middle C comes out at 261.63 Hz rather than the old-fashioned 256 Hz. This is done to allow a singing voice to match modern musical instruments. A = 440 Hz is called “Concert Pitch”
“Breathy Voice”
The remaining control is “Breathiness” -- a slider and percentage display just below the musical note display. When the vocal folds are vibrating, they may not completely close at nominal closure for a variety of reasons. The commonest case is for female speech. A small triangle of the vocal fold gap remains open during the closure phase and allows air to leak through. This introduces a breathy noise (similar to light aspiration) during voiced sounds. The effect is characteristic of female speech and is called “breathy voice”. Readers, especially male readers, must be aware of the appeal of a “husky voice” which is an extreme version of this consistent sex marker. This is the main reason for including this control since one aim of the TRM is to emulate male, female and child voices accurately. Breathiness is an important parameter (along with tube length) for this exercise. The parameter can be varied from 0 to 10% of the excitation energy.
Explorations and the creation of .trm data files
Note: this section is only a sketch and needs expanding. A paper describing the generation of the current TRM posture database is currently in preparation, and will be an important reference for a revised and expanded section.
Creating TRM “postures”
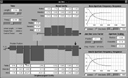
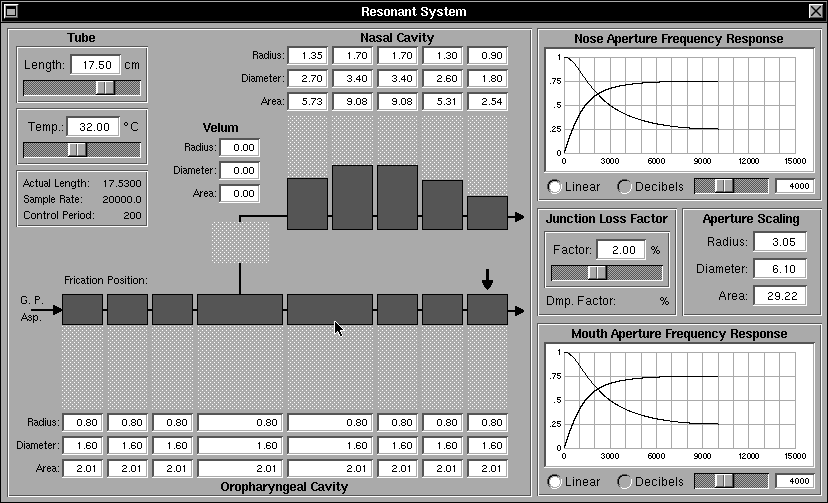
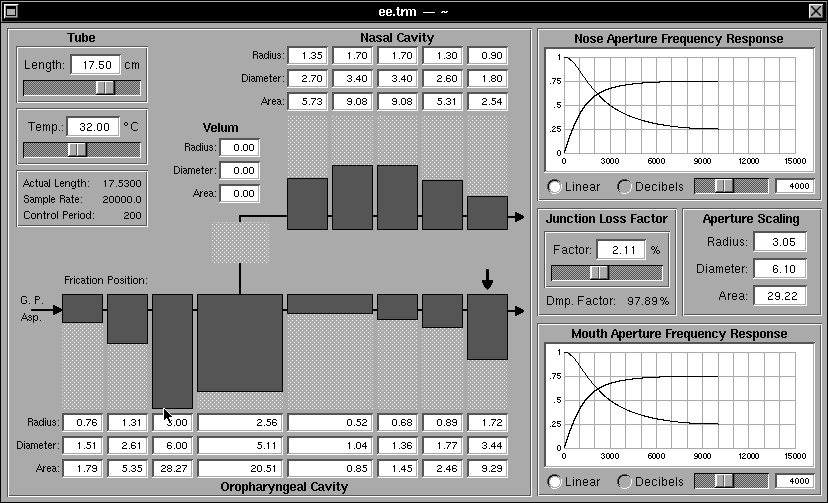
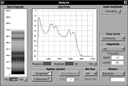 Fig 18a: The Resonant System panel showing oro-pharyngeal tube sections set up for an “ee-like” sound
Fig 18a: The Resonant System panel showing oro-pharyngeal tube sections set up for an “ee-like” sound
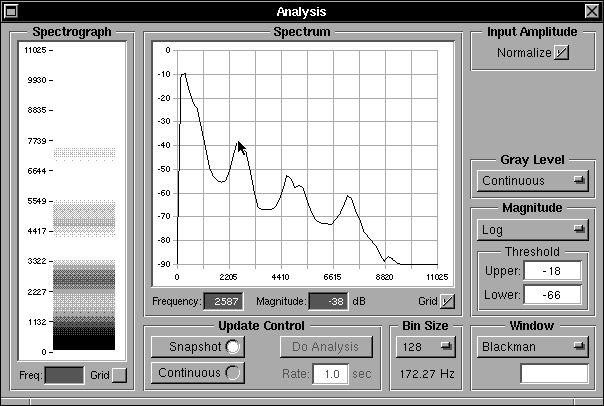
Fig 18b: The Analysis panel showing the broad band spectrum of the “ee-like” sound
To set up the TRM configuration for a sound only requires that you have some knowledge of articulatory phonetics and can interpret this knowledge as tube radii and the expected spectral output. Appendix A provides a set of data for the entire nominal postural structure of spoken English (additional detail such as co-articulation and some acoustic events are taken care of by the Monet/GnuSpeech parameter generation system). The regions, starting at r1 correspond to: 1 to 3 -- the pharynx; 4 -- the region either side of the velum; 5 -- the front part of the oral cavity behind the alveolar ridge; 6 -- the region around
the alveolar ridge; 7 -- the region from the alveolar ridge to the teeth; and 8 -- the region from the teeth to the outside of the lips. Note that regions 4 and 5 are twice the length of the others, which are 1.6 cm long for a 16 cm vocal tract.
Lip opening affects r8. Jaw rotation affects r4 through r8. Tongue height (low to high) and position (back to front) affect r2 through r7 in a constrained way -- a high back vowel, for example, leads to narrowing of r2 through r4 and opening of r6/7. Exactly what effect it has on r5 will depend on the details of the articulation. A reasonable shape can be tried, preferably using articulatory data from the literature as a guide, and the effect can be checked by carrying out an analysis to determine the spectrum of the resulting sound. There is no precise data for the DRM control system, and the TRM control regions are not exactly aligned with these regions anyway. However, the match is close enough to get excellent results in synthetic speech with a low data rate compared to trying to control a 40 section tube model.
The paper “Real time articulatory synthesis ...” (Hill et al. 1995) includes a diagram showing how constrictions at the various DRM control regions affect the formants. It can be used as a guide when modifying the tube configurations to get a better spectral match to a given real sound. Vowel sounds are fairly straightforward. The data in Wells (1963) is a useful starting point for British English. The data published by Peterson and Barney (1952) is more appropriate to General American. Dealing with consonants, especially stop sounds, is more problematical since they may have no steady-state spectrum, or the spectrum may be masked by nasalisation, etc. However, knowing the apparent origins of the formant transitions can be a guide, as can listening to the resulting postures in continuous speech synthesis. Green's paper (1959) and Liberman's paper (1955) are helpful in this respect while Strevens (1960) gives some feel for the fricative characteristics. There is a wealth of literature, much of it from earlier times -- given the change in interest to synthesis by concatenated segments. The papers cited give an entry into the literature that is likely to be helpful, but the task is likely to prove difficult for any language in which the user's linguistic/phonetic knowledge is deficient.
Figure 18a shows the resonant system configured to produce a sound similar to “ee” in English. Figure 18b shows the broad band analysis of the resulting output. Note the low first formant, and relatively high formants 2 and 3, charateristic of this kind of sound. If a slightly different “ee-like” sound were required, the constrictions could be modified, knowing their effect in different DRMs from the paper quote above. Changes in pitch and breathiness could be tried and other parameters varied to listen to the effects of different conditions and see the spectral effects of changes that changed the spectrum. Then the .trm file could be saved (see next section), and read into the Monet system where the sound could be tried as part of continuous speech, listening to the result and performing a spectrographic analysis to understand the effect “in context”. This also highlights the fact that, for successful database creation, Synthesizer and Monet interact and must be used iteratively and in concert.
Note that only the parameters affecting the individual sound would be saved and transferred. Pitch is managed as a parameter separate from the TRM postures within the Monet system (except for micro-intonation special events) and a number of parameters are so-called “utterance rate” parameters, that do not vary from posture to posture (for example, tube length, temperature, pulse shape, mouth and nose aperture frequency responses, noise cross-mix, throat transmission, and junction loss factor).
Even the durations of the speech postures are outside the scope of Synthesizer. Posture durations control rhythm which is modelled as part of the Monet system along with the pitch variations that control intonation. Rhythm and intonation interact. Together they form prosody and, as previously noted, they directly and significantly affect meaning. A discussion of the issues is outside the scope of this manual, but some insight into the approach taken for the TextToSpeech Experimenter Kit may be gained from reports related to research at the U of Calgary and other places that underpins the system prosody (Halliday 1970; Hill 1978; Jassem, et al 1984; and Taube-Schock 1993).

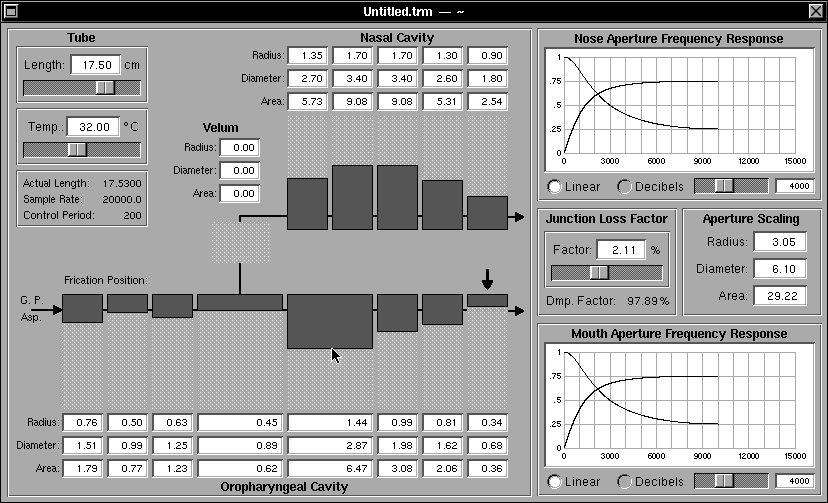
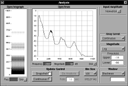 Fig 19a: The Resonant System panel showing oro-pharyngeal tube sections set up for an “oo-like” sound
Fig 19a: The Resonant System panel showing oro-pharyngeal tube sections set up for an “oo-like” sound
Fig 19b: The Analysis panel showing the broad band spectrum of the “oo-like” sound
Figures 19a and 19b show the same Resonant System and Analysis sub-system views as Figures 18a and 18b but for an “oo-like” English sound. The two configurations and analyses can be compared with each other, and with the data provided for the relevant postures used for text-to-speech synthesis that are listed in Appendix A.
The various static controls, such as Glottal Source waveform, Throat Transmission and Mouth and Nose Aperture Frequency Response are generally best left at their default values, unless you have a particular objective in mind. The effects can be tried, out of interest. The one exception is the “Pitch” frequency. It is sometimes easier to hear the quality of the sound, for listening tests, with a value that is different to the default value. The author prefers a lower value.
The Noise Crossmix is of use in sounds such as /z/, where the combination of vibrating vocal folds and vocal tract constriction produce both voicing, and a modulation of the fricative noise.
At present, the Tube length cannot be reduced below about 15 cm in the NeXT implementation because the computation rate is not sufficient to deal with shorter tube lengths (which means higher frequencies in the tube). Even when the system is not generating output, reducing the tube length too far will crash the system. Porting to modern systems with far higher computation rates and with DSP-like instructions available on the main processor, should eliminate this problem.

Saving .trm data
 Fig 20: Document Menu
Fig 20: Document Menu
References
ATAL, BS and SL HANAUER (1971) Speech analysis and synthesis by linear prediction of the speech wave, J Acoust Soc Amer, 50 (2), Aug, pp 637-633.
CARRE, R & S CHENNOUKH (1993) Vowel-Consonant-Vowel modeling by superposition of consonant closure on Vowel-to-Vowel gestures 3rd Seminar on Speech Production: Models and Data, Saybrook Point Inn May 11-13 1993
CARRE, R, S CHENNOUKH & M MRAYATI (1992) Vowel-consonant-vowel transitions: analysis, modeling and synthesis Proc ICSLP 92 (Int. Conf. of Spoken Language Processing), Banff, Alberta, pp 819-822
CARRE, R & MRAYATI, M (1994) Vowel transitions, vowel systems, and the Distinctive Region Model. in Levels in Speech Communication: Relations and Interactions. Elsevier: New York
CARRE, R, B LINDBLOM & P MACNEILAGE (1994) Acoustic contrast and the original of the human vowel space Acoust Soc Amer meeting, Cambridge MA, paper 3pSP
COOK, PR (1991) Identification of control parameters in an articulatory vocal tract model with applications to the synthesis of singing PhD Thesis, Stanford University, Dept of Electrical Eng, September
DUNN, HK (1950) The calculation of vowel resonances, and an electrical vocal tract J Acoust Soc Amer 22 pp 740-753
FANT, CGM & S PAULI (1974) Spatial characteristics of vocal tract resonance mod
es. SCS 74 (Speech Communication Seminar, Stockholm, Aug 1-3 1974, pp 121-133
FANT, G (1956) On the predictability of formant levels and spectrum envelopes from formant frequencies. In For Roman Jakobson. Mouton: The Hague, 109-120
FANT, CGM (1960) Acoustic theory of speech production Mouton: The Hague
FANT, G & PAULI, S (1974) Spatial characteristics of vocal tract resonance models. Proceedings of the Stockholm Speech Communication Seminar, KTH, Stockholm, Sweden
FLANAGAN, JL (1972) Speech analysis, synthesis and perception Springer-Verlag: New York, ISBN 0-387-05561-4, 444 pp (Second Edition)
GREEN, PS (1959) Consonant-vowel transitions: a spectrographic study Travaux de l'Institut de Phonétique de Lund, (also in Studia Linguistica XII 1958 number 2) (available in the Essex University library, UK)
HALLIDAY, MAK (1970) A course in spoken English: intonation. Oxford University Press 134pp
HECKER, MHL (1962) - Studies of nasal consonants with an articulatory speech synthesiser. J Acoust Soc Amer 34, (2), February
HILL, DR (1978) Some results from a preliminary study of British English speech rhythm Research report 78/26/5, Dept of Comp Sci, U of Calgary, 24 pp
HILL, DR, MANZARA, L & TAUBE-SCHOCK, C-R (1995) Real-time articulatory speech-synthesis-by-rules. Proc. AVIOS '95 14th Annual International Voice Technologies Conf, San Jose, 12-14 September 1995, 27-44.
HILL, DR (1991) A conceptionary for speech and hearing in the context of machines and experimentation, Comp Sci Dept Report, 2nd edition 2004.
JASSEM, W, DR HILL & IH WITTEN (1984) Isochrony in English speech: its statistical validity and linguistic relevance in Intonation, Accent and Rhythm: studies in discourse phonology (D Gibbon & H Richter, eds), de Gruyter: Berlin & New York, ISBN 3-11-009832-6
LAWRENCE, W (1953) The synthesis of speech from signals which have a low information rate. In Communication Theory, Butterworth: London, 460-469
LAWRENCE, W (1954) The experimental synthesis of speech from parameters Signals Research and Development Establishment Report: Christchurch, UK
LIBERMAN, AM, P DELATTRE & FS COOPER (1955) Acoustic locii and transitional cues for 34 consonants J Acoust Soc Amer 27 (4), July
LIBERMAN, AM, INGEMANN, F, LISKER, L, DELATTRE, P & COOPER, FS (1959) Minimal rules for synthesising speech. J Acoust Soc Amer 31 (11), 1490-1499, Nov
MANZARA, L & DR HILL (2002) Pronunciation Guide (http://www.cpsc.ucalgary.ca/~hill/papers/monman/pronguid.html)
MARKEL, JD & AH GRAY (1976) Linear Prediction of Speech Springer-Verlag: New York, ISBN 3-540-07563-1
PETERSON, GE & BARNEY, HL (1952) Control methods used in the study of vowels J. Acoust Soc Amer 24 (3), 175-184, March. (Also Bell Monograph 1982)
POTTER, RK, GA KOPP & H GREEN (1947) Visible Speech Bell Telephone laboratories: Murray Hill, New Jersey (Dover edition 1966 LCCCN 65-23130, by which time Harriet Green had married George Kopp, so the authors were Potter, Kopp and Kopp)
ROSENBERG, AE (1971) Effect of glottal pulse shape on the quality of natural vowels J Acoust Soc Amer 49 583-590
TAUBE-SCHOCK, C-R (1993) Intonation for computer speech output MSc Thesis, Dept of Comp Sci, U of Calgary, September (available from University Microfilms) (note this is the same person as “Craig Schock”)
SHANNON, C (1948) The mathematical theory of communication Bell System Technical Journal, July & October
SMITH JO III (2004) Physical audio signal processing (URL: http://www-ccrma.stanford.edu/~jos/waveguide/) May
STEVENS, K, S KASOWSKI & CGM FANT (1953) An electrical analog of the vocal tract J Acoust Soc Amer 25 pp 743-742
STREVENS, P (1960) Spectra of fricative noises in human speech Language & Speech, 3 (1), Jan/Mar
TOLKIEN JRR (1966) The Return of the King George Allen & Unwin: London, UK (Unwin Paperbacks 1978 combined edition ISBN 0-04-823229-7, page 620: Pippin speaking to Gandalf as he is carried away from his encounter with the Palatír at Orthanc, read by David R. Hill; and analysed by Neal Reid under the NRC of Canada grant A5261)
WELLS, JC (1963) A study of the formants of the pure vowels of British English Progress Report, University College, London, UK, July
WHITFIELD, IC & EF EVANS (1965) Behaviour of Neurones in the unanaesthetised auditory cortex of the cat J. Neurophysiology 28, 655-672
WITTEN IH (1982) Principles of Computer Speech Academic Press: London, ISBN 0-12-760760-9, 286 pp
Appendix A: Derivation of and values for parameter data for Tube Resonance Model postures
(Note: This is the complete raw posture data contained in the GnuSpeech database. The Monet Manual, Appendix D contains the equivalent formant and timing data. Since the timing data varies between marked and unmarked versions of a given posture, each posture has two entries in that table.
The TRM parameter data for the 65 or so articulatory postures that follow were experimentally derived during the last three months of 1994 by the author and Leonard Manzara working together. The details of the derivation should be included in a paper in preparation but involved: (1) analysis of real speech using a Kay Sonagraf and the Sonagram App on the NeXT computer; (2) use of real speech data from publications such as Wells' vowel data (Wells 1963); (3) the adjustment of the DRM regions and other parameters in the Tube Resonance Model using Synthesizer, starting from a knowledge of articulatory phonetics and the effect of constrictions in the eight DRM regions on formant frequencies; (4) the fact that the vocal tract has structural and dynamic constraints of the configurations that are possible; (5) the analysis of the TRM output using the Analysis sub-system of Synthesizer and a comparison of this with the analyses from real speech; and (6) the use of the Monet system to test the effectiveness of the postures derived, in continuous synthetic speech, by listening to a good variety of phonetic contexts. Development of the Monet context rules and rewrite rules proceeded in parallel, and the steps were iterated as necessary.
It will be noted that the r1 DRM region is always set to a 0.8 cm radius. In fact it probably need not have been included as a varying parameter because it really only determines the relative scale. Similar results could be obtained for all postures with different values of r1 leading to different, but geometrically similar values of the other 7 regions for each posture. This is presently an untested hypothesis, but one in which we have considerable confidence.
Region r1 corresponds to the first DRM region above the glottis. Region r8 corresponds to the last region before the mouth orifice. In some postures, the fricative spectral parameters (fricVol, fricPos, fricCF and fricBW) are set, with the fricative volume (fricVol) at zero. This is because the particular posture is associated with a fricative noise burst in which the fricative volume is controlled by a special event parameter profile rather than the regular parameter control using the fricative volume value. The fricative volume parameter settings are generally rather low. The noise balances within the TRM implementation need some attention. It causes some problems in the parameter displays within the Monet system because the values are hardly visible at values which give acceptable output energy. This and the small range to work with also makes adjusting fricatives, especially voiced fricatives during database creation somewhat tricky, especially for the placement and volume of special events.
The velum “closed” value default is 0.1 -- very slightly open. The same is true of closure for /t,d,k,g/ at their points of articulation (r6), /k,g/ (r5), and lip closure for /b,p/ (associated with r8, though this is a bit of a fudge -- it may be better to close the mouth orifice and leave r8 to be manipulated independently; mouth closure could be substituted for the r1 parameter to keep the number of dynamically variable parameters the same). The slight opening avoids some slight artifacts without affecting the articulations.
It is important to realise that perceiving TRM postures is both static and dynamic. Vowels, which can be represented as a stand-alone steady state sound without losing any of their identity, can be heard when the TRM posture (articulation) is appropriately set up, though the ear and brain soon become habituated to the noise which begins to lose its identity. Short bursts of the sound are more convincing, but still lack the dynamic variation of real speech. However, when you come to steady state consonant postures (articulations), many of the cues we use in perceiving them are simply absent because the cues are dynamic (changes in formant frequency, or fricative characteristics as the sound approaches and leaves the posture, and noise bursts). Some consonant postures preclude any sound because the oro-pharyngeal and nasal passages are completely closed, though some sound may escape for a short time through the throat tissues if the vocal folds are vibrating -- so called “voice bar” in the Visible Speech terminology. If the closure is maintained, the flexible parts of the tract fill up and air can no longer flow, so the vocal folds stop vibrating. Consonant postures can only be tested as part of continuous speech, which is what we had to do. The locus theory of consonant perception (Liberman 1955, for example) derives from this essential basic fact. To the extent that such locii (the frequencies from which or to which formant transitions appear to move in speech spectrograms) exist, they are related to the postures associated with the consonants. The phenomenon of co-articulation -- the influence of context on the actual configuration in continuous speech -- ensures that there are no fixed locii for consonants any more than there are fixed formant combinations for vowels. However, there is a grain of truth in the idea of consonant locii. The GnuSpeech system context rules are designed to allow such co-articulation effects to be included. Green (1959) provides a comprehensive spectrographic study of consonant-vowel transitions.
The pronunciations associated with the posture symbols below, which were designed to be mnemonic and easily typed, have been rendered in terms of both the International Phonetic Association and Websters phonetic symbols, together with other helpful information, in an on-line pronunciation guide (Manzara & Hill 2002). Note that only one version of each posture is provided. The marked, unmarked and other (e.g. syllabic) versions have the same TRM parameter values. Only the durations differ. Durations are relevant to the Monet/GnuSpeech level rather than the TRM level. Also, as already noted, some acoustic characteristics (for example, bursts of aspiration or fricative noise, and co-articulation effects) of the sounds are managed by the rules and prototypes in the Monet/GnuSpeech system and are, as far as the TRM is concerned “hidden”.
Appendix B: GNU Free Documentation Licence
GNU Free Documentation License
Version 1.1, March 2000
Copyright (C) 2000 Free Software Foundation, Inc.
59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or other
written document "free" in the sense of freedom: to assure everyone
the effective freedom to copy and redistribute it, with or without
modifying it, either commercially or noncommercially. Secondarily,
this License preserves for the author and publisher a way to get
credit for their work, while not being considered responsible for
modifications made by others.
This License is a kind of "copyleft", which means that derivative
works of the document must themselves be free in the same sense. It
complements the GNU General Public License, which is a copyleft
license designed for free software.
We have designed this License in order to use it for manuals for free
software, because free software needs free documentation: a free
program should come with manuals providing the same freedoms that the
software does. But this License is not limited to software manuals;
it can be used for any textual work, regardless of subject matter or
whether it is published as a printed book. We recommend this License
principally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work that contains a
notice placed by the copyright holder saying it can be distributed
under the terms of this License. The "Document", below, refers to any
such manual or work. Any member of the public is a licensee, and is
addressed as "you".
A "Modified Version" of the Document means any work containing the
Document or a portion of it, either copied verbatim, or with
modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of
the Document that deals exclusively with the relationship of the
publishers or authors of the Document to the Document's overall subject
(or to related matters) and contains nothing that could fall directly
within that overall subject. (For example, if the Document is in part a
textbook of mathematics, a Secondary Section may not explain any
mathematics.) The relationship could be a matter of historical
connection with the subject or with related matters, or of legal,
commercial, philosophical, ethical or political position regarding
them.
The "Invariant Sections" are certain Secondary Sections whose titles
are designated, as being those of Invariant Sections, in the notice
that says that the Document is released under this License.
The "Cover Texts" are certain short passages of text that are listed,
as Front-Cover Texts or Back-Cover Texts, in the notice that says that
the Document is released under this License.
A "Transparent" copy of the Document means a machine-readable copy,
represented in a format whose specification is available to the
general public, whose contents can be viewed and edited directly and
straightforwardly with generic text editors or (for images composed of
pixels) generic paint programs or (for drawings) some widely available
drawing editor, and that is suitable for input to text formatters or
for automatic translation to a variety of formats suitable for input
to text formatters. A copy made in an otherwise Transparent file
format whose markup has been designed to thwart or discourage
subsequent modification by readers is not Transparent. A copy that is
not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain
ASCII without markup, Texinfo input format, LaTeX input format, SGML
or XML using a publicly available DTD, and standard-conforming simple
HTML designed for human modification. Opaque formats include
PostScript, PDF, proprietary formats that can be read and edited only
by proprietary word processors, SGML or XML for which the DTD and/or
processing tools are not generally available, and the
machine-generated HTML produced by some word processors for output
purposes only.
The "Title Page" means, for a printed book, the title page itself,
plus such following pages as are needed to hold, legibly, the material
this License requires to appear in the title page. For works in
formats which do not have any title page as such, "Title Page" means
the text near the most prominent appearance of the work's title,
preceding the beginning of the body of the text.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either
commercially or noncommercially, provided that this License, the
copyright notices, and the license notice saying this License applies
to the Document are reproduced in all copies, and that you add no other
conditions whatsoever to those of this License. You may not use
technical measures to obstruct or control the reading or further
copying of the copies you make or distribute. However, you may accept
compensation in exchange for copies. If you distribute a large enough
number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and
you may publicly display copies.
3. COPYING IN QUANTITY
If you publish printed copies of the Document numbering more than 100,
and the Document's license notice requires Cover Texts, you must enclose
the copies in covers that carry, clearly and legibly, all these Cover
Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on
the back cover. Both covers must also clearly and legibly identify
you as the publisher of these copies. The front cover must present
the full title with all words of the title equally prominent and
visible. You may add other material on the covers in addition.
Copying with changes limited to the covers, as long as they preserve
the title of the Document and satisfy these conditions, can be treated
as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit
legibly, you should put the first ones listed (as many as fit
reasonably) on the actual cover, and continue the rest onto adjacent
pages.
If you publish or distribute Opaque copies of the Document numbering
more than 100, you must either include a machine-readable Transparent
copy along with each Opaque copy, or state in or with each Opaque copy
a publicly-accessible computer-network location containing a complete
Transparent copy of the Document, free of added material, which the
general network-using public has access to download anonymously at no
charge using public-standard network protocols. If you use the latter
option, you must take reasonably prudent steps, when you begin
distribution of Opaque copies in quantity, to ensure that this
Transparent copy will remain thus accessible at the stated location
until at least one year after the last time you distribute an Opaque
copy (directly or through your agents or retailers) of that edition to
the public.
It is requested, but not required, that you contact the authors of the
Document well before redistributing any large number of copies, to give
them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document under
the conditions of sections 2 and 3 above, provided that you release
the Modified Version under precisely this License, with the Modified
Version filling the role of the Document, thus licensing distribution
and modification of the Modified Version to whoever possesses a copy
of it. In addition, you must do these things in the Modified Version:
- A. Use in the Title Page (and on the covers, if any) a title distinct
from that of the Document, and from those of previous versions
(which should, if there were any, be listed in the History section
of the Document). You may use the same title as a previous version
if the original publisher of that version gives permission.
- B. List on the Title Page, as authors, one or more persons or entities
responsible for authorship of the modifications in the Modified
Version, together with at least five of the principal authors of the
Document (all of its principal authors, if it has less than five).
- C. State on the Title page the name of the publisher of the
Modified Version, as the publisher.
- D. Preserve all the copyright notices of the Document.
- E. Add an appropriate copyright notice for your modifications
adjacent to the other copyright notices.
- F. Include, immediately after the copyright notices, a license notice
giving the public permission to use the Modified Version under the
terms of this License, in the form shown in the Addendum below.
- G. Preserve in that license notice the full lists of Invariant Sections
and required Cover Texts given in the Document's license notice.
- H. Include an unaltered copy of this License.
- I. Preserve the section entitled "History", and its title, and add to
it an item stating at least the title, year, new authors, and
publisher of the Modified Version as given on the Title Page. If
there is no section entitled "History" in the Document, create one
stating the title, year, authors, and publisher of the Document as
given on its Title Page, then add an item describing the Modified
Version as stated in the previous sentence.
- J. Preserve the network location, if any, given in the Document for
public access to a Transparent copy of the Document, and likewise
the network locations given in the Document for previous versions
it was based on. These may be placed in the "History" section.
You may omit a network location for a work that was published at
least four years before the Document itself, or if the original
publisher of the version it refers to gives permission.
- K. In any section entitled "Acknowledgements" or "Dedications",
preserve the section's title, and preserve in the section all the
substance and tone of each of the contributor acknowledgements
and/or dedications given therein.
- L. Preserve all the Invariant Sections of the Document,
unaltered in their text and in their titles. Section numbers
or the equivalent are not considered part of the section titles.
- M. Delete any section entitled "Endorsements". Such a section
may not be included in the Modified Version.
- N. Do not retitle any existing section as "Endorsements"
or to conflict in title with any Invariant Section.
If the Modified Version includes new front-matter sections or
appendices that qualify as Secondary Sections and contain no material
copied from the Document, you may at your option designate some or all
of these sections as invariant. To do this, add their titles to the
list of Invariant Sections in the Modified Version's license notice.
These titles must be distinct from any other section titles.
You may add a section entitled "Endorsements", provided it contains
nothing but endorsements of your Modified Version by various
parties--for example, statements of peer review or that the text has
been approved by an organization as the authoritative definition of a
standard.
You may add a passage of up to five words as a Front-Cover Text, and a
passage of up to 25 words as a Back-Cover Text, to the end of the list
of Cover Texts in the Modified Version. Only one passage of
Front-Cover Text and one of Back-Cover Text may be added by (or
through arrangements made by) any one entity. If the Document already
includes a cover text for the same cover, previously added by you or
by arrangement made by the same entity you are acting on behalf of,
you may not add another; but you may replace the old one, on explicit
permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License
give permission to use their names for publicity for or to assert or
imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under this
License, under the terms defined in section 4 above for modified
versions, provided that you include in the combination all of the
Invariant Sections of all of the original documents, unmodified, and
list them all as Invariant Sections of your combined work in its
license notice.
The combined work need only contain one copy of this License, and
multiple identical Invariant Sections may be replaced with a single
copy. If there are multiple Invariant Sections with the same name but
different contents, make the title of each such section unique by
adding at the end of it, in parentheses, the name of the original
author or publisher of that section if known, or else a unique number.
Make the same adjustment to the section titles in the list of
Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections entitled "History"
in the various original documents, forming one section entitled
"History"; likewise combine any sections entitled "Acknowledgements",
and any sections entitled "Dedications". You must delete all sections
entitled "Endorsements."
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents
released under this License, and replace the individual copies of this
License in the various documents with a single copy that is included in
the collection, provided that you follow the rules of this License for
verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute
it individually under this License, provided you insert a copy of this
License into the extracted document, and follow this License in all
other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate
and independent documents or works, in or on a volume of a storage or
distribution medium, does not as a whole count as a Modified Version
of the Document, provided no compilation copyright is claimed for the
compilation. Such a compilation is called an "aggregate", and this
License does not apply to the other self-contained works thus compiled
with the Document, on account of their being thus compiled, if they
are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these
copies of the Document, then if the Document is less than one quarter
of the entire aggregate, the Document's Cover Texts may be placed on
covers that surround only the Document within the aggregate.
Otherwise they must appear on covers around the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may
distribute translations of the Document under the terms of section 4.
Replacing Invariant Sections with translations requires special
permission from their copyright holders, but you may include
translations of some or all Invariant Sections in addition to the
original versions of these Invariant Sections. You may include a
translation of this License provided that you also include the
original English version of this License. In case of a disagreement
between the translation and the original English version of this
License, the original English version will prevail.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document except
as expressly provided for under this License. Any other attempt to
copy, modify, sublicense or distribute the Document is void, and will
automatically terminate your rights under this License. However,
parties who have received copies, or rights, from you under this
License will not have their licenses terminated so long as such
parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions
of the GNU Free Documentation License from time to time. Such new
versions will be similar in spirit to the present version, but may
differ in detail to address new problems or concerns. See
http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number.
If the Document specifies that a particular numbered version of this
License "or any later version" applies to it, you have the option of
following the terms and conditions either of that specified version or
of any later version that has been published (not as a draft) by the
Free Software Foundation. If the Document does not specify a version
number of this License, you may choose any version ever published (not
as a draft) by the Free Software Foundation.
--------------end of Free Documentation Licence copy------
Page last updated 08-07-27.