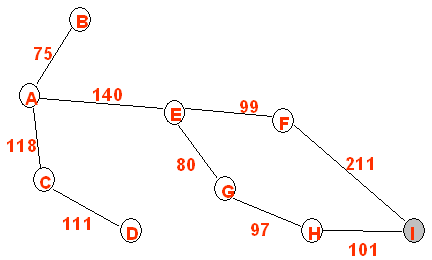
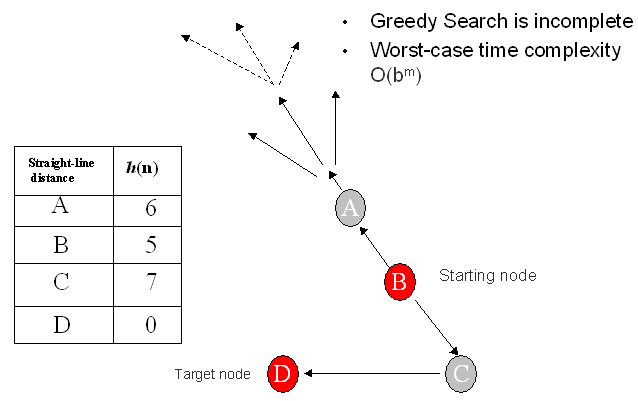
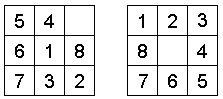
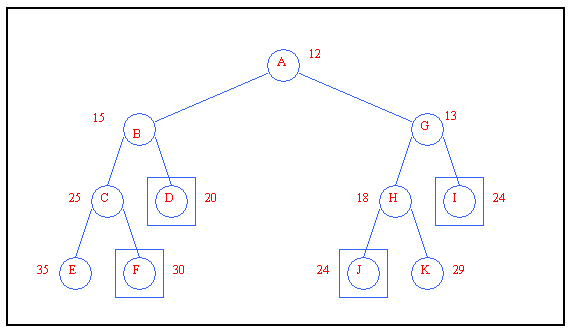
It is worth mentioning an advantage of the iterative improvement
algorithm. That is, it can save some memory space because it keeps
track of only the current state.
The iterative improvement algorithms divide into two major classes.
The first one is called the Hill-climbing search, also called
gradient
descent.
The second one is called the Simulated annealing.
4.1 Hill-climbing search
The Hill-climbing search algorithm is a loop that continually moves
in the direction of increasing value. The algorithm only records
the state and its evaluation instead of maintaining a search tree. It takes
a problem as an input, and it keeps comparing the values of the
current
and the next nodes. The next node is the highest-valued successor
of the current node. If the value of the current node is greater
than the next node, then the current node will
be returned. Otherwise, it will go deeper to look at the
next
node of the next node.
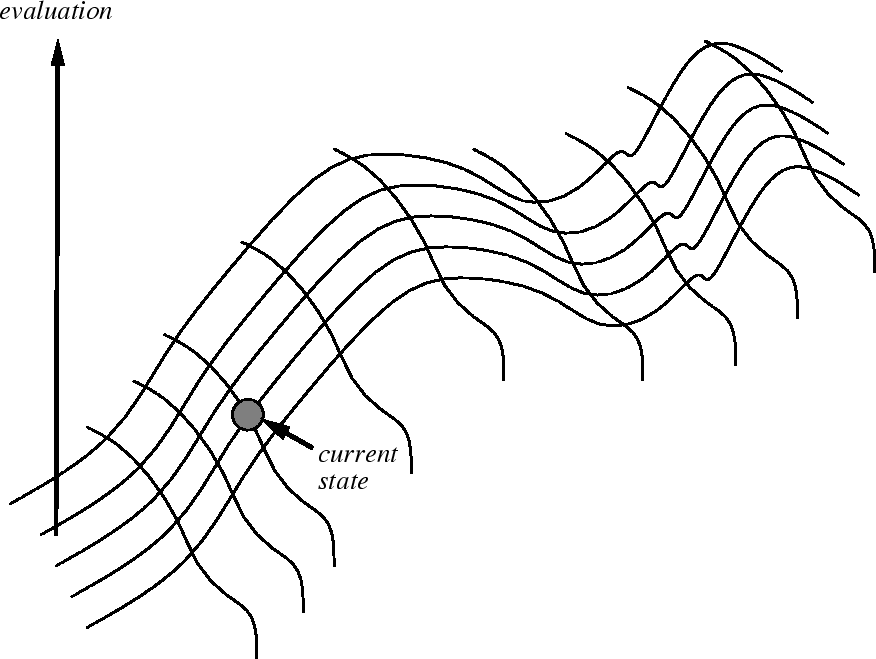
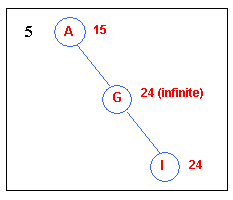
The peaks are found on a surface of states where height is defined
by Hill-climbing function.

The Hill-climbing search algorithm
If it encounters a situation that there is more than one best successor
to choose from, it will randomly select a certain one.
There are three well-known drawbacks for this situation:
Local maxima, plateaux, and ridges.
4.1.1 Local Maxima
Local maxima is a peak that is lower than the highest peak
in the state space.
When a local maxima is reached, the algorithm will halt even a solution
has not been reached yet.
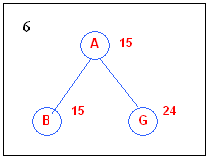
4.1.2 Plateaux
A plateaux is an area of the state space where the neighbors
are about the same height.
In such a situation, a random walk will be generated.
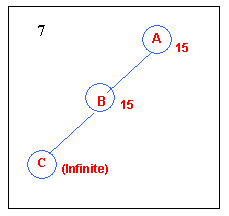
4.1.3 Ridges
A ridge may have steeply sloping sides towards the top, but
the top only slopes gently towards a peak.
In this case, the search makes little progress unless the top is directly
reached, because it has to go back
and forth from side to side.
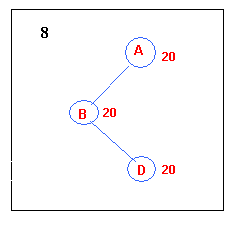
It must be possible to encounter a situation that no further progress can
be made from one certain starting point. If this happens, the Random
restart hill-climbing is the obvious thing to do. As the name says,
it randomly generates different starting points over again until it halts.
It saves the best result found so far. And it can eventually find
out the optimal solution if enough iterations are allowed.
As a matter of fact, and obviously, the fewer local maxima, the quicker
it finds a good solution. But usually, a reasonably good solution
can be found after a small number of iterations.
4.2 Simulated Annealing
The Simulated annealing takes some downhill steps to escape the
local maxima, and it picks random moves instead of picking the best move.
If the move actually improve the situation, it will keep executing the
move. Otherwise, it will make the moves of a probability less than
one. When the end the searching is close, it starts behaving like
hill-climbing.
The word "annealing" is originally the process of cooling a liquid until
it freezes. The Simulated-annealing function takes a problem
and a schedule as inputs. Here, schedule is a mapping
determining how fast the temperature should be lowered. Again, the
algorithm keeps comparing the values of the current and the next
nodes,
but here, the next node is a randomly selected successor of the
current
node.
It also maintains a local variable T which is the temperature controlling
the probability of downward steps. By subtracting the values of
the current node from the next node to obtained the difference Delta-E,
the algorithm can determine the probability of the next move. If
Delta-E
is
greater than zero, then the
next
node will be looked at. Otherwise,
the probability for the next
node to be looked at is
e to
the power Delta-E
over T. In other word, the variable
Delta-E is actually the amount by which the evaluation is worsened.

The Simulated Annealing search algorithm
4.3 Applications
in Constraint Satisfaction Problems
The general algorithm for solving constraint satisfaction problems
is to first assign values to all variables, then apply modifications to
the current configuration by assigning new values to some certain variables
towards a solution.
An 8-queen problem would the best example to use to illustrate here.
The goal of the 8-queens problem is to place eight queens on a chessboard
such that no queen attacks any other.
The best algorithm for solving this problem would be the min-conflicts
heuristic repair method. The characteristics of the algorithm is to firstly
repair inconsistencies in the current configuration, and then select a
new value for a variable that results in the minimum number of conflicts
with other variables.
Detailed Steps:
1. One by one, find out the number of conflicts between the
inconsistent variable and other variables.
2. Choose the one with the smallest number of conflicts to make a move.
3. Repeat previous steps until all the inconsistent variables have
been assigned with a proper value.
To apply these
steps on an example from Pg. 114 of the textbook Artificial
Intelligence: A Modern Approach,
Stuart
Russell - Peter Norvig - 1995.



State I
State II
State III
In State I, the 2 queens on fourth and eighth rows are attacking each
other. To find a new position for the eighth queen, we need to firstly
find out the number of conflicts between this queen and all other queens.
The numbers of conflicts would be the numbers shown on the eighth column
in State I. Why the number on the first row is two? It is because
that if we move the eighth queen up to the first row, there will be two
other queens, one on the first row and the other on the third row, attacking
it. And so on for the rest positions.
Now we are to choose a position with the smallest number of conflicts
to place the eighth queen. The fact is that it is possible to have more
than one best choice. The third row with one conflict would our choice
for convenience.
Then we have moved over to State II. Since the eighth queen had
moved to the third queen's position, we now need to look for a new position
for the third queen. So again, we repeat finding out the numbers
of attacking queens to this third queen. As same as above, the numbers
of conflicts would be the numbers shown on the sixth column in State II.
The number three is on the first row because that if we move the third
queen up to the first row, there will be three other queens, one on the
first row, second on the fifth row, third on the third row (the originally
eighth queen), attacking it. And so on for the rest positions. But
obviously, the last row would be the only best choice because it is the
only one has no conflict. Therefore, we move the third queen down
to the last row, then we have found the optimal solution.
This min-conflicts heuristic repair method has been proved to be surprisingly
effective. We have just seen how it can solve the above problem in
two steps. And it has been recorded to be able to solve a million-queens
problem in an average of less than 50 steps.